Il sistema spiegato come si deve
Il tema dell’inclusione (e dell’esclusione) di alcuni specifici titoli dagli indici sta diventando sempre più determinante nei processi di investimento. Alcuni investitori ritengono importante poter escludere alcuni titoli che non rispettano, per esempio, alcuni principi etici ritenuti ineludibili o che potrebbero essere semplicemente identificati come concorrenti o addirittura potrebbero decidere di escludere i propri titoli quando gli investitori sono loro stessi società quotate. Altri investitori in alternativa, vorrebbero invece investire solo in panieri di titoli altamente speculativi.
L’industria fintech ha risposto a questa esigenza proponendo strumenti per il direct indexing. Con questa nuova metodologia l’investitore non utilizza più gli ETF per investire indirettamente in indici di società quotate, ma impiega invece indici creati ad hoc che permettono di negoziare direttamente panieri di titoli acquistandoli in maniera frazionata. Si tratta di una formula decollata con alcune piattaforme, che si sono dimostrate molto sensibili ad assecondare la speculazione focalizzando l’attenzione dei propri clienti sulla negoziazione di strumenti particolarmente di moda o gettonati in un determinata fase.
Con l’impego sempre più pervasivo dell’intelligenza artificiale (IA) nel settore finanziario per valutare gli esiti probabilistici degli investimenti, oggi siamo in grado di creare indici tematici investibili a gestione attiva, dotati intrinsecamente di nuovi modelli di selezione, sviluppati per individuare in anticipo i titoli che sono caratterizzati dal potenziale inespresso più elevato. Il direct indexing apre un nuovo universo di prospettive: mentre fondi ed ETF tematici sono soggetti a preventive indagini commerciali e ad un lungo iter di approvazione della strategia prima di raggiungere il mercato, gli indici, ed in particolare gli indici a gestione attiva sono potenzialmente investibili istantaneamente.
La lunga fase di progettazione del sistema ci ha portato ad identificare la necessità di utilizzare almeno tre singole classi di applicazione per le tipologie di intelligenza artificiale da impiegare per la gestione attiva degli indici e posti sotto il controllo di un Supervisor:
- Unsupervised Machine Learning: Per le applicazioni di tecniche di feature extraction e feature selection. Per la riduzione della dimensionalità delle informazioni ed evidenziazione delle più significative, secondo i nostri criteri di gestione del rischio.
- Machine Learning: Per le applicazioni tattiche, fortemente specializzate nel raggiungere un singolo obiettivo.
- Swarm Intelligence & Deep Learning: Per le applicazioni strategiche, orientate alla comprensione del quadro generale e alla supervisione di tutte le attività accessorie che permettono di gestire il risultato in un quadro allargato con l’obiettivo di massimizzare il rapporto tra rendimento e rischio per ogni singolo indice.
Il rendimento è una grandezza facilmente misurabile; il rischio, invece, risulta difficilmente misurabile in quanto è una grandezza soggettiva la cui percezione è influenzata da molteplici fattori. In assenza di precise valutazioni, è difficile comprendere il giusto equilibrio tra rendimento e rischio.
Siamo abituati a pensare che rischio e rendimento siano due valori che crescono insieme. Ma non è così.
Possiamo in estrema sintesi dividere i rischi associati agli investimenti in :
- Rischi accettabili
- Rischi inaccettabili
- Rischi inevitabili
Utilizzando le tecniche di feature extraction e feature selection abbiamo selezionato preventivamente, ed incluso nell’universo di investimento generale, solo strumenti finanziari che presentassero rischi accettabili, escludendo strumenti illiquidi o scambiati su mercati non regolamentati.
Intelligenza Artificiale
L’intelligenza artificiale (IA) è stata definita come “l’abilità di una macchina di mostrare capacità umane quali il ragionamento, l’apprendimento, la pianificazione e la creatività” nello specifico contesto in cui è richiesto a dei sistemi informatici di capire il proprio ambiente, mettersi in relazione con quello che percepiscono, risolvere problemi e agire verso un obiettivo specifico analizzando gli effetti delle azioni precedenti in autonomia e adattando il proprio comportamento.
Nessuna delle tre singole classi di applicazione per le tipologie di intelligenza artificiale che utilizziamo è prevalente rispetto alle altre. Anche se non avevamo inizialmente alcun preconcetto su quale tecnologia utilizzare, non abbiamo escluso a priori l’impiego parziale di tecnologie di deep learning assimilabili all’intelligenza artificiale forte, in aggiunta a quelle di machine learning che già impiegavamo. Ci siamo infine imposti di non avere mai, a nessun livello di calcolo, delle “black box” che ci avrebbero impedito di rendere trasparente e reversibile il processo decisionale utilizzato, mentre creavamo un ponte tra i due mondi (analisi quantitativa classica vs intelligenza artificiale).
Nella filosofia dell’intelligenza artificiale, l’intelligenza artificiale “forte” è l’idea che opportune forme di intelligenza artificiale possano veramente ragionare e risolvere autonomamente i problemi; l’intelligenza artificiale forte sostiene che è possibile per le macchine diventare sapienti o coscienti di sé, senza necessariamente mostrare processi di pensiero simili a quelli umani.
In contrasto con l’intelligenza artificiale forte, l’intelligenza artificiale “debole” è basata sul “come se”, ovvero agisce “come se” avesse una mente e si riferisce all’uso di programmi e algoritmi per studiare o risolvere specifici problemi o ragionamenti che non possono essere compresi pienamente o che, in alcuni casi, superano i limiti delle capacità cognitive umane. Diversamente dall’intelligenza artificiale forte, quella debole non realizza una auto consapevolezza e non dimostra il largo intervallo di livelli di abilità cognitive proprio dell’uomo, ma è esclusivamente un risolutore di problemi specifico parzialmente intelligente.
Vediamo, in sintesi, quali attività svolgono le tre singole classi di applicazione per tipologia di intelligenza poste sotto il controllo del Supervisor:
- Unsupervised Machine Learning: Il sistema calcola giornalmente per ogni strumento finanziario analizzato, a chiusura mercato, una serie di indicatori di raggruppamento per classe di performance, rischio, rating e liquidità.
- Machine Learning: Il sistema calcola giornalmente per ogni strumento finanziario analizzato, a chiusura mercato, lo stato binario che indica la convenienza teorica di comprare tale strumento a partire dal giorno successivo o di non comprarlo (in alternativa, di venderlo se è stato comprato in precedenza) esprimendo una valutazione dinamica (denominata score) degli stessi, minimizzando il numero di operazioni e massimizzando il rapporto tra rendimento e rischio. A complemento del processo decisionale il sistema calcola per ogni strumento analizzato un modello probabilistico valido per le 4 settimane successive.
- Swarm Intelligence & Deep Learning: Il sistema partendo dall’universo di investimento definito dal progettista, ed impiegando tecniche di swarm intelligence (intelligenza dello sciame), calcola giornalmente a chiusura mercato le eventuali modifiche da apportare alla composizione del portafoglio modello, utilizzando le variazioni dello stato binario e dello score prodotte dalla intelligenza artificiale tattica.
Il Supervisor coadiuvato da un team di selezione, utilizzando un motore di ricerca e selezione dedicato, definisce e mantiene aggiornato periodicamente l’universo di investimento per ogni indice attivo elaborato, il numero massimo di elementi che lo rappresentano, supervisiona inclusioni ed esclusioni di singole asset class e/o strumenti e impone i limiti di volatilità, turnover, correlazione e concentrazione.
Machine Learning
Ogni strumento finanziario viene associato ad uno stato binario che indica la convenienza teorica di comprare tale strumento o di non comprarlo (o di venderlo se è stato comprato in precedenza) a partire dal giorno successivo al prezzo di apertura o a valore di NAV. Non sono previste vie di mezzo (riduci o incrementa).
I due stati possibili sono “long” e “flat”. Non vengono dunque mai implementate strategie “short” (che sono caratterizzate da rischi inaccettabili ossia da perdite possibili superiori al capitale nominale impiegato)
L’intelligenza artificiale viene impiegata per determinare, per ogni strumento finanziario analizzato, la probabilità di salita o discesa per ognuno dei 20 giorni di mercato successivi al giorno in cui viene rilevato l’ultimo valore di negoziazione.
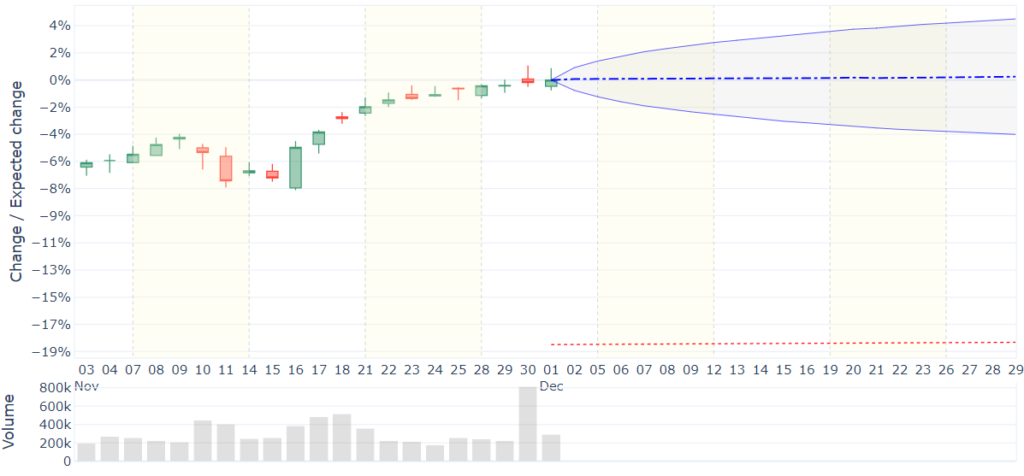
Imponendo al modello di calcolo dei segnali una limitazione alla frequenza delle operazioni e ponendo come obiettivo medio un acquisto e una vendita annuale (turnover = 1), l’esito cumulato del vantaggio prospettico misurato è sufficiente per individuare delle aree vantaggiose all’interno del range di volatilità atteso. Il compito dell’intelligenza artificiale è quello di individuare tra la molteplicità degli andamenti ciclici espressi da ogni strumento, quello più significativo in termini di estensione del range considerato.
L’esito probabilistico medio calcolato per oltre 50’000 strumenti finanziari, ha evidenziato la presenza di 12 aree statisticamente significative all’interno di ogni ciclo rappresentabili sul quadrante di un ipotetico orologio le cui ore sono sincronizzate con l’evoluzione ciclica tra minimi e massimi, per l’ampiezza del ciclo più significativa individuata dai sistemi di Machine Learning per ogni strumento analizzato.
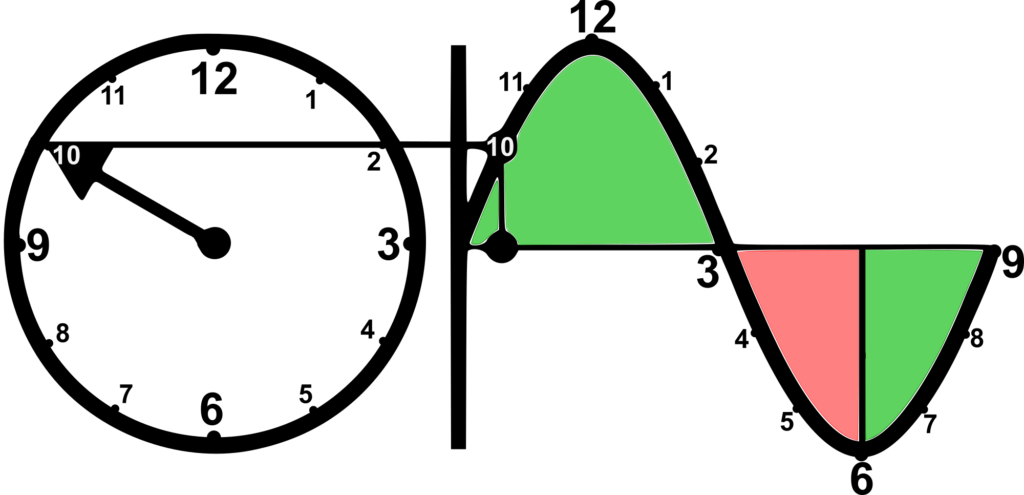
Le aree possono essere descritte come segue:
- un’area di massimo relativo del ciclo (ore 12)
- un’area di minimo relativo del ciclo (ore 6)
- 5 aree nella fase discendente tra il massimo e il minimo del ciclo
- 5 aree nella fase ascendente tra il minimo e il massimo del ciclo.
Gli esiti probabilistici hanno evidenziato che da ore 6 a ore 3, passando per ore 12, gli esiti probabilistici per i 20 giorni di mercato successivi sono favorevoli; quelli tra ore 3 e ore 6 sono invece sfavorevoli.
La strategia globale più vantaggiosa individuata dall’intelligenza artificiale è sostanzialmente basata su 4 regole:
- Il sistema compra al massimo del ciclo a ore 12 ad ogni occorrenza.
- Il sistema compra al minimo del ciclo a ore 6 (o in prossimità) alla prima occorrenza (In caso di operazione chiusa in perdita, il sistema attende per l’operazione successiva a ore 6, il completamento di un ciclo completo che passa da ore 12).
- Il sistema vende a ore 3 (o in prossimità) ad ogni occorrenza.
- Il sistema vende al raggiungimento dello stop prefissato.
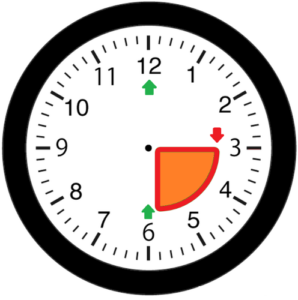
In aggiunta alle regole precedenti può verificarsi la circostanza in cui le operazioni possono anche venire chiuse in profitto (tipicamente a ore 12) in presenza di rendimenti attesi annuali conseguiti in tempi molto brevi (inferiori alla settimana).
L’addestramento dei modelli viene effettuato pesando maggiormente gli eventi più recenti. Per il singolo strumento viene adottato inizialmente un modello fortemente generalizzato che eredita la parametrizzazione dalla media del cluster di appartenenza. In seguito i successivi addestramenti avverranno solo in presenza di un cambiamento del segnale.
Prima che il cambiamento venga confermato la rete viene riaddestrata (ovviamente senza che i segnali precedenti all’addestramento possano venire cambiati).
Dopo il riaddestramento solo 2 circostanze possono verificarsi:
- La rete conferma il segnale
- La rete nega il nuovo segnale. (In questa circostanza nulla accade in termini operativi a parte l’affinamento della rete stessa.)
Il livello di stop viene aggiornato quotidianamente e non può mai essere inferiore al livello di stop calcolato a partire dal primo giorno di applicazione del corrente segnale di acquisto.
Al raggiungimento del livello “target” di profitto, lo stop viene significativamente avvicinato all’ultimo valore dello strumento.
Il sistema calcola giornalmente per ogni strumento finanziario analizzato, a chiusura mercato, una serie di indicatori di raggruppamento:
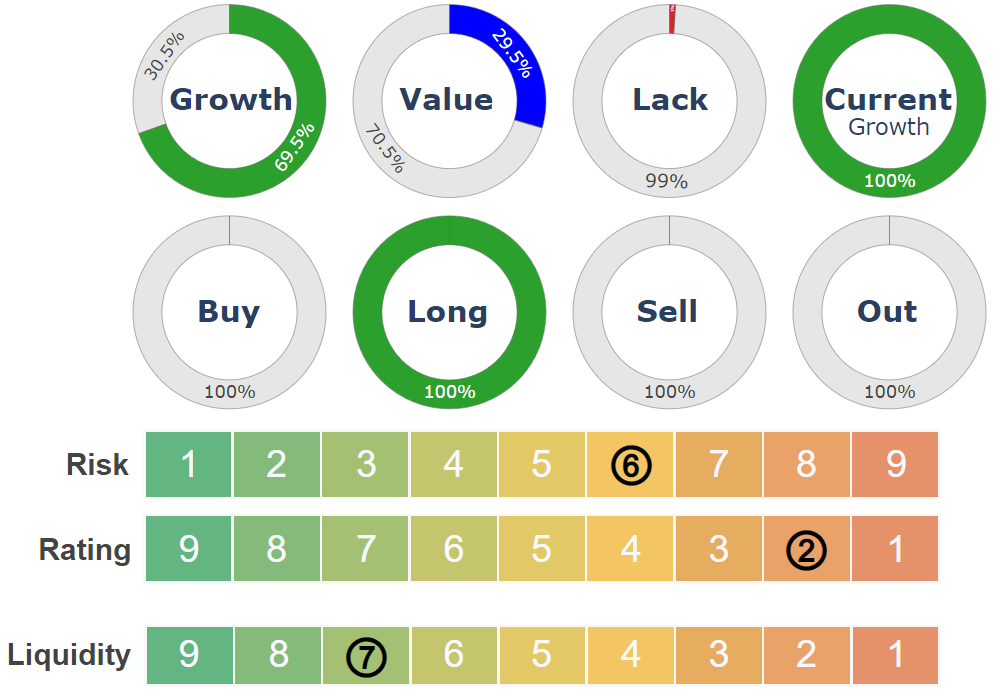
- Categorizzazione del tipo di performance storica a 5 anni e attuale (Growth, Value, Lack)
- Trend (Buy, Long, Sell, Out)
- Rischio (da 1 = Min, a 9 = Max), calcolato utilizzando la metodologia proposta da ESMA per il calcolo del “synthetic risk and reward indicator” (SRRI) pubblicato nel Key Investor Information Document (KID)
- Rating (da 9 = Max, a 1 = Min)
- Liquidità (da 9 = Max, a 1 = Min)
- Fase ciclica “Clock” (da 1 a 12)
- Prezzo di entrata (solo in presenza di Trend Long)
- Prezzo di stop (superamento al ribasso del prezzo di chiusura, solo in presenza di Trend Long)
Gli indicatori sono calcolati anche per ogni entità disponibile di aggregazione statistica o funzionale di più strumenti (e dunque anche per gli indici stessi), che vengono trattati al pari di qualsiasi altro strumento analizzato.
Ogni indicatore è il risultato di una formula (ossia un algoritmo) che utilizza solo ed esclusivamente le serie storiche (prezzi e volumi) dello strumento analizzato.
Gli effetti di questa scelta sono estremamente positivi per quanto riguarda l’esito probabilistico ottimale, perché è basato sulla neutralità tecnologica (riassumibile in “stesso servizio, stesso rischio, stesse regole”) che è in antagonismo alla umana tendenza di ricorrere a stereotipi quando siamo chiamati a prendere decisioni, senza renderci conto di essere condizionati dal bias cognitivo (o distorsione cognitiva).
Oltre agli indicatori appena elencati, per ogni strumento viene prodotto giornalmente anche un commento in lingua inglese, ottenuto automaticamente per mezzo di un generatore testuale.
Swarm Intelligence & Deep Learning
Il sistema, per ogni indice, partendo dall’universo di investimento definito dal Supervisor e dalle regole da esso impostate, impiegando tecniche di swarm intelligence (intelligenza dello sciame), calcola giornalmente a chiusura mercato le eventuali modifiche da apportare alla composizione dell’indice, utilizzando le variazioni dello stato binario e degli score prodotti dal sistema decisionale (Machine Learning – intelligenza artificiale tattica) adottato per ogni singolo strumento finanziario.
Le due regole base adottate dal sistema sono:
- Ciascuno strumento presente nell’universo di investimento può entrare nell’indici per il peso prefissato, in presenza di un segnale long e in assenza dell’attivazione di una regola di esclusione.
- Tutti gli strumenti presenti in ogni indice devono uscire completamente in presenza di un segnale short.
Le regole di esclusione sono le seguenti:
- No Cash – E’ stata esaurita la liquidità disponibile per il nuovo segnale
- Max El. – E’ stato raggiunto il numero massimo di elementi previsti per l’indice
- R.S. % – La forza relativa dello strumento è troppo bassa rispetto a quella dei componenti dello stesso cluster di correlazione presente nell’universo di investimento.
- Correl. % – La correlazione con gli strumenti già presenti in portafoglio è troppo alta tenendo conto dei seguenti 3 vincoli:
- Livello iniziale % di attivazione (sino ad una determinata % complessiva non viene attivato il controllo)
- Livello % di peso del cluster (sino ad un determinato peso % di strumenti che superano il livello di correlazione non viene attivato il controllo)
- Livello soglia % (il livello massimo di correlazione ammesso tenendo conto dei due vincoli precedenti di attivazione).
Il calcolo del peso prefissato è molto semplice. Ogni strumento entra nell’indice in proporzione al numero massimo di strumenti che l’indice può accogliere e non in proporzione alla sua capitalizzazione di mercato.
- L10: Massimo 10 strumenti al 10% ciascuno
- L20: Massimo 20 strumenti al 5% ciascuno
- L40: Massimo 40 strumenti al 2.5% ciascuno
Uno strumento entrato al 10% può raggiungere il 20% (per esempio) nel caso in cui il suo valore raddoppi in assenza di movimento degli altri componenti. Ma nel caso in cui uscisse, rientrerà in seguito nuovamente al 10%.
Il livello di Cash (liquidità) che deve essere mantenuto non investito è sostanzialmente la decisione più importante presa dal sistema di calcolo e si ottiene sottraendo a 100% il valore percentuale di “Target Long” calcolato.
Esempio
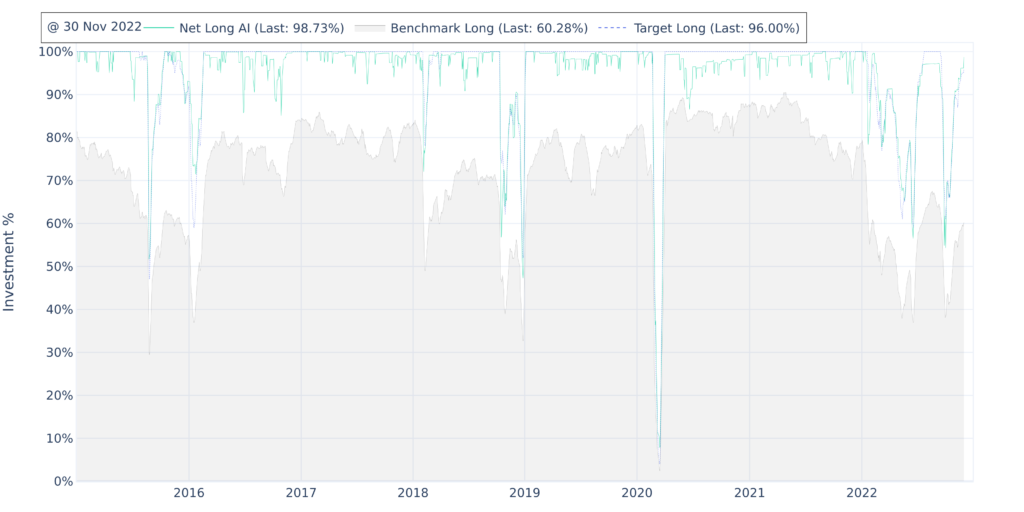
Il calcolo parte da un valore medio che è indicato sul grafico, che rappresenta la percentuale di investimenti nel tempo e che è etichettato come “benchmark long”. Il valore più recente indica la media percentuale dei titoli presenti nell’universo di investimento adottato per il calcolo dei componenti dell’indice, che presentano un trend “long”.
Guardiamo l’indice di sintesi di 40 titoli basato sull’universo S&P 500 al 30 Nov 2022. Con 500 titoli presenti nell’universo e 236 a fine giornata calcolati con trend “long”, il valore “benchmark long” era 236/500 = 0.472, ossia 47.2%.
Nel grafico possiamo vedere che in media il “benchmark long” ha un valore vicino al 60%. Questo valore se utilizzato direttamente avrebbe lasciato in media il 40% di liquidità disponibile per effetto della non inclusione dei titoli “Out”. Ma con questa regola difficilmente avremmo potuto battere sul medio/lungo periodo qualsiasi strategia di Buy&Hold (compra e tieni) attuata sull’intero indice. Il dato “benchmark long” ci è sembrato dunque in origine inutilizzabile. Ma ci sbagliavamo.
Abbiamo chiesto al sistema di non usare il dato “benchmark long” e di provare ad effettuare un gran numero di simulazioni su centinaia di indici con frame temporali differenti per ottenere la percentuale di liquidità ideale da mantenere giorno per giorno ossia il “Target Long”. Ci ha davvero stupito scoprire che la percentuale ideale convergeva verso il valore minore tra 100% e “benchmark long” moltiplicato per 1.6 (il numero irrazionale 1.6180339887… che è conosciuto anche come sezione aurea o rapporto aureo o numero aureo o costante di Fidia o proporzione divina, nell’ambito delle arti figurative e della matematica).
Quindi, 47.22% x 1.61 = 76% ossia livello di Cash = 100% – 76% = 24%
In altre parole, o nuovi segnali long arriveranno globalmente in seguito e si ridurrà (progressivamente sino a zero) il livello di cash obbligatorio da mantenere, o la prima regola di esclusione (No Cash – E’ stata esaurita la liquidità disponibile per il nuovo segnale) impedirà al modello di aggiungere nuovi elementi all’indice.
E’ sufficiente che il 62.5% dei titoli di un singolo universo di investimento presentino trend “Long” per portare la liquidità bloccata a zero. (62.5% * 1.6 = 100%)
Disquisizioni filosofiche
Una delle critiche che viene spesso mossa al mondo fintech riguarda l’assimilabilità dei sistemi e modelli di AI utilizzati, alle logiche tipiche del gioco (L’idea che “il gioco” abbia una connotazione negativa è riconducibile alla frase “Giocare in borsa”, usata dagli investitori principianti per indicare l’ottenuto accesso, simulato o reale, agli alti e bassi del mercato).
“L’ AI non conosce davvero le aziende. Chi le ha visitate e studiate sì!” … “Le AI sono così diffuse che ormai giocano una contro l’altra” … “Io non voglio un portafoglio (indice) di esiti probabilistici. Io voglio un portafoglio di aziende sane!”.
Nella prima metà del 2022 un gran numero di aziende a larghissima capitalizzazione, note e conosciute da tutti, hanno dimezzato in media la loro quotazione a partire dal massimo del loro ciclo espansivo. Ma non sono cambiate le aziende, dato che il loro fatturato ha continuato a crescere e che non hanno smesso di distribuire utili, è cambiato il flusso di acquisti che ha sostenuto per almeno un quinquennio le loro quotazioni. C’è stata una inversione di ciclo ossia un movimento che l’intelligenza artificiale ha perfettamente riconosciuto.
Normalmente tutti giochi sono dotati di regole convenzionali e prestabilite che rappresentano l’essenza del gioco; Le regole devono essere esplicite, ossia definite, comunicate, accettate e condivise da tutti i partecipanti prima che il gioco abbia inizio; Perché il gioco sia equo, le regole devono essere insegnate, apprese e riconoscibili da tutti i partecipanti. “Giocare in borsa” è uno dei giochi più praticati al mondo e allo stesso tempo è anche quello che ha il maggior numero di partecipanti ignari di quali siano le vere regole del gioco, ossia di come si possibile (e necessario) calcolare i vantaggi o gli svantaggi associati alla scelta di investire in uno strumento finanziario rispetto a un altro.
Senza voler affrontare le tematiche relative alla corretta distribuzione di asset class in portafoglio (Azioni, obligazioni, materie prime, metalli preziosi, valute, opzioni, crypto), prendiamo, solo per esempio, in relazione all’esito probabilistico del “gioco”, una forma di distorsione della valutazione (bias) causata dal pregiudizio: la scelta di selezionare per gli investimenti azionari solo investimenti responsabili (IR), ossia la pratica, in base alla quale agli obiettivi tipici della gestione finanziaria (l’ottimizzazione del rapporto tra rischio e rendimento in un dato orizzonte temporale), vengono affiancate considerazioni di natura ambientale, sociale o di governance (ESG-environmental, social, governance). Tipicamente la modalità con cui gli IR vengono realizzati è il cosiddetto screening, che consiste nel selezionare i titoli da inserire in un portafoglio finanziario attraverso l’analisi del comportamento delle società emittenti secondo criteri ESG. La selezione viene fatta in base a dei criteri IR: criteri negativi (o di esclusione) e criteri positivi (o di inclusione).
I criteri negativi prevedono l’analisi di condizioni che, quando si verificano, comportano l’esclusione della società in esame. Si tratta quindi di una limitazione della libertà di acquisto da parte di un investitore che si impegna a non investire in determinate aziende e in determinati settori che presentano problematiche di ordine ESG come per esempio produzione e commercio di armi, produzione e distribuzione del tabacco o delle biotecnologie per usi alimentari, il settore chimico e petrolifero che possono essere considerati non compatibili dal punto di vista ambientale. Cosa succede al “gioco” in un mese come il gennaio 2022 quando il differenziale di rendimento tra 2 categorie di titoli raggiunge il 25% (i tecnologici ESG -15% e i petroliferi non ESG +10%)? Il gioco diventa improvvisamente un “cattivo gioco”.
L’intelligenza artificiale, relativamente agli indici, che nel loro universo di investimento comprendevano tutti i titoli liquidi investibili (quindi con tutte le “carte da gioco” a disposizione) ha invece giocato un “buon gioco”. La differenza è tutta qui. Nella mancanza di pregiudizi.
Dieci anni fa l’intelligenza artificiale era guardata con sospetto perché nell’immaginario collettivo veniva rappresentata visivamente da robot, ossia da macchine più o meno antropomorfe (cioè che presentano sembianze umane nelle funzionalità e nei movimenti) che avrebbero potuto improvvisamente ribellarsi agli umani; ma nonostante i timori, si prevedeva che nel corso del decennio successivo, in alcuni settori come quello del trading azionario, l’intelligenza artificiale avrebbe completamente sostituito l’operatività umana.
Nel frattempo, il suo impiego è diventato talmente pervasivo, che abbiamo smesso di sentire la necessità di darle una forma. Ma se proprio dobbiamo immaginare fisicamente una intelligenza artificiale senza ricorrere nuovamente all’esempio dell’automobile a guida autonoma, lo smartphone dovrebbe essere considerato il suo involucro più diffuso.
Purtroppo, spesso e inconsapevolmente, tendiamo a trascurare l’evoluzione in corso quando proviamo a misurare la nostra abilità con altri umani, ignorando di competere, invece, contro intelligenze artificiali addestrate allo scopo. In tempi recenti, negli Stati Uniti, gli “umani” che nel settore finanziario competono a mani nude contro sistemi informatici progettati esplicitamente per batterli, sono addirittura raddoppiati rispetto alla rilevazione di 10 anni fa. Umani attirati da applicazioni di trading gratuite e da un mercato rialzista, caratterizzato dalla crescita esplosiva delle quotazioni di società tecnologiche durante la pandemia che ha lasciato a casa milioni di americani, con poco da fare e con soldi regalati dal governo.
L’evidenza statistica ci dice che circa l’80% dei trader ogni anno sistematicamente perde denaro, e il dato statistico è universalmente noto da quando l’ESMA (European Securities and Markets Authority) ha obbligato i broker ad evidenziare il dato riguardante i propri clienti.
La previsione di dieci anni fa che profetizzava un mercato in cui ci sarebbero stati solo programmi informatici a competere tra di loro si è dimostrata errata.
Anche nei settori come l’Hft (High-frequency trading, trading condotto dai computer) dove in teoria i sistemi dovrebbero competere esclusivamente tra di loro, i perdenti continuano ad essere i clienti umani che utilizzano le app di trading gratuito, che accettano in cambio delle commissioni a zero di rendere visibile il flusso dei loro ordini a società specializzate in Hft. Quindi come dobbiamo considerare l’utilizzo dell’intelligenza artificiale nell’High-frequency trading? Gli operatori Hft utilizzano, nella loro attività, essenzialmente la forza bruta. Non hanno bisogno di intelligenza artificiale. Quando aprono una posizione e la chiudono in pochi millisecondi hanno la quasi certezza di ottenere un profitto, che di fatto è una perdita per chi negozia in coda alle loro operazioni. Vincono installando reti ultraveloci e i macchinari in prossimità fisica dei server di borsa, per poter anticipare chi ha connessioni più distanti e quindi più lente. Ma soprattutto in associazione con alcuni broker (più volte sanzionati dalle autorità di vigilanza) spiano gli ordini dei clienti che stanno per arrivare a essere negoziati sul mercato.
Da qualche anno le gestioni patrimoniali assistite da modelli di intelligenza artificiale hanno trovato la loro collocazione all’interno di un quadro normativo che gradualmente sta cambiando. Un crescente numero di gestori e professionisti illuminati ha contribuito a spiegare i vantaggi di queste nuove tecnologie ai propri clienti che le hanno accolte con entusiasmo.
Le intelligenze artificiali autoadattive che, senza esitazioni ed emozioni sono focalizzate solo ed esclusivamente sui movimenti dei prezzi sono riuscite a proteggere gli investitori nelle crisi più recenti; sia nel finale del 2018 che nel 2020, ma soprattutto nel 2022 hanno operato in maniera soddisfacente sia nelle attività di riduzione del rischio che in quelle di ausilio alla crescita del rendimento, e in assenza di rendimento alla riduzione sostanziale delle perdite.
Altri sistemi costruiti per analizzare dati differenti invece non hanno garantito gli stessi risultati positivi. Ci sono intelligenze artificiali progettate e specificamente addestrate per analizzare a fondo i dati di bilancio delle aziende. È facile intuire come, al netto dei bilanci falsi di società come Wirecard, abbiano potuto comportarsi dopo che, in poche settimane, una buona parte della popolazione mondiale ha quasi smesso di recarsi fisicamente al lavoro, di rifornirsi di carburante, di pranzare al ristorante, di andare a vedere le partite o di andare al cinema. Si sono ritrovate totalmente cieche al cambiamento di prospettiva.
Ci sono poi le intelligenze artificiali addestrate per inseguire scandagliando i social media le notizie significative riguardanti singole aziende e operare sui mercati di conseguenza. Ma quando l’intera rete è stata monopolizzata da un flusso monotematico di lamentazioni, anche il loro potere previsionale viene fortemente compromesso.
Ci sono infine le intelligenze artificiali addestrate per operare in contesti più specializzati come quello energetico che si affidano a misurazioni di ogni tipo, compresi i consumi e le disponibilità di stoccaggio. Ma anche questi si ispirano a modelli noti e non potevano certo prevedere che ad un certo punto qualcuno sarebbe stato disposto a regalare il petrolio, anzi addirittura a pagare chi, in un determinato momento, mettesse a disposizione un deposito libero per stoccarlo.
Chiediamoci a questo punto se ci sono e quali sono le classi di investimento che rispondono in maniera più efficiente all’uso di queste tecnologie. Le azioni più liquide dei maggiori indici internazionali, infatti, si prestano agevolmente a essere impiegate sia in strategie di gestione di portafogli a bassa rotazione che per attività di trading ad alta rotazione. Le classi di investimento peggiori invece sono il Forex (ossia il mercato delle valute) e le singole obbligazioni.
La spiegazione è semplice: le azioni sono estremamente liquide e vengono negoziate in mercati regolamentati e i prezzi di scambio sono disponibili a tutti i partecipanti. Le valute e le obbligazioni solo in particolari circostanze. La liquidità è e rimane il fattore più importante per poter eseguire i segnali proposti dai sistemi dotati di intelligenza artificiale, senza subire gravi penalizzazioni durante le fasi di negoziazione.
Nessun consulente e nessun gestore può, in prospettiva, pensare di poter offrire il miglior servizio possibile semplicemente affidandosi a studi, notizie e al proprio intuito. Tra qualche anno nessuna automobile potrà venire prodotta senza una sufficiente dotazione di automatismi di assistenza alla guida. Lo stesso accadrà con la consulenza finanziaria.
Nessuno specialista singolarmente possiede la capacità previsionale per competere con quello che il mercato esprime collettivamente come entità globale: i vincitori e i vinti del futuro, le nuove tecnologie, l’evoluzione degli stili di vita, le nuove tendenze, i picchi epidemici, l’esito delle guerre, i cambiamenti politici e le leadership nazionali o per singoli prodotti, sono tutti individuabili nelle variazioni di valore che il mercato quotidianamente attribuisce agli strumenti finanziari a loro associabili. Settori, paesi, temi e leader di mercato variano costantemente il loro valore rispetto all’interesse e alle aspettative che riescono a suscitare in una vasta platea di analisti, investitori e trader. Quando i vincitori raggiungono le copertine dei giornali, il mercato sta già scegliendo i prossimi.
L’intelligenza artificiale non ha, e probabilmente non avrà mai, la possibilità di conoscere il futuro, e dunque non dirà mai (con parole sue, ovviamente): “come avevamo previsto” (e nemmeno “non potevamo prevederlo”), ma è assolutamente in grado di valutare al meglio delle sue possibilità di calcolo cosa sta accadendo ora, nell’immediato presente. E sappiamo che una parte significativa del presente continuerà, per inerzia, a propagarsi nel futuro prossimo.